
Associated Press Capstone Project:
Building Metadata Ground Truth
Welcome to our Harvard University, School of Engineering and Applied Sciences (SEAS), Institute for Applied Compuatational Science (IACS), Spring 2018 - AC297R Capstone Project.
Please see the contact section at the end of this page to contact any member of our team.
About the Associated Press (AP)
The AP is an independent non-profit news cooperative headquartered in New York City. While the organization is well known for its reporting and journalism, it also offers a suite of metadata services. Clients can submit their own content to receive relevant metadata tags in order to identify important topics, increase search relevance, and deliver targeted results. The current metadata system tags approximately 100,000 pieces of media content every day.
For more information about the AP and its metadata services, please see our references.
Project Overview
Existing System
Currently, the AP Tagging Service returns tags from a list of standardized vocabularies known as
the AP News Taxonomy. The News Taxonomy is a set of hierarchically structured topics and names
across five broad categories: Person, Geography, Company, Organization, and Subject. Person contains
a list of individuals who are well-known nationally or globablly, with a special focus on the United
States. Geography is a set of hierarchical place names, ranging from continents and countries to
cities and towns. Company contains over 50,000 publicly traded companies, while Organization focuses
on a diverse range of sectors, from government organizations and political institutions to
universities and sports teams. Subject contains broad topics like Crime to the specific
subtopics like illegal firearms. In total, there are over 165,000 possible tags. These lists are
manually maintained and updated.
The Tagging Service identifies phrases in submitted content that match items in the News
Taxonomy. It also uses a set of manually-created if-then rules to identify other topics that
might apply. These tags are added as metadata at the beginning of each piece of content passed
through the AP's system.
Figure 1 shows a preview of the rules used by AP's current system.
Current Limitations
We identified three main limitations in the AP's current tagging system.
First, the existing human-created if-then rules are lengthy, complicated to write, and difficult
to maintain. They also generally rely on simple checks such as the presence or absence of
certain words, which, without context, can lead to mistakes. One example of this can be seen in
Figure 2. This article is about the USS Constitution, a wooden-hulled, three-masted heavy frigate of the United
States Navy, named after the US Constitution. The article itself does not have anything to do with
the US Constitution, but the first topic highlighted by AP's metadata system is "Constitutions,"
which is clearly incorrect.
In addition to the rules, the entire set of possible tags depends on manual maintenance. If a person does not add a tag to the News Taxonomy, it will never appear in metadata, no matter how relevant it may be to an article. For example, this flaw is particularly apparent in sports articles, which comprise a majority of all coverage. Teams and player rosters change frequently, and if someone is not constantly updating the News Taxonomy, the appropriate people and organizations will not be identified and tagged accordingly.
Finally, the existing tagging system can only identify the presence or absence of a topic. This binary system cannot score, rank, or sort the topics it identifies. This makes it impossible to understand the degree to which a particular piece of content is about a given topic.
Overall, these limitations we found are certainly not desirable, as they could lead to inaccurate search results, ultimately reducing the disoverability of content and increasing the number of customer complaints the AP receives.
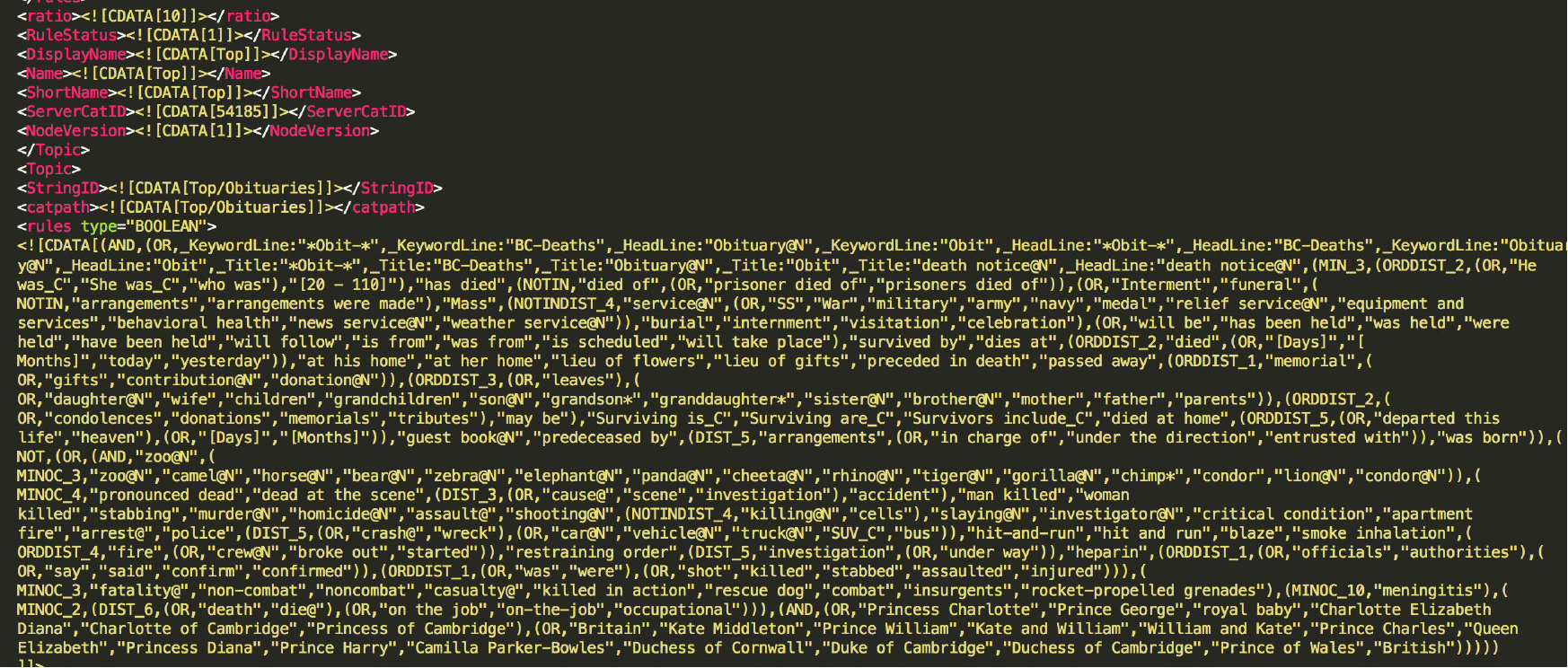
Fig 1. A preview of AP's rules
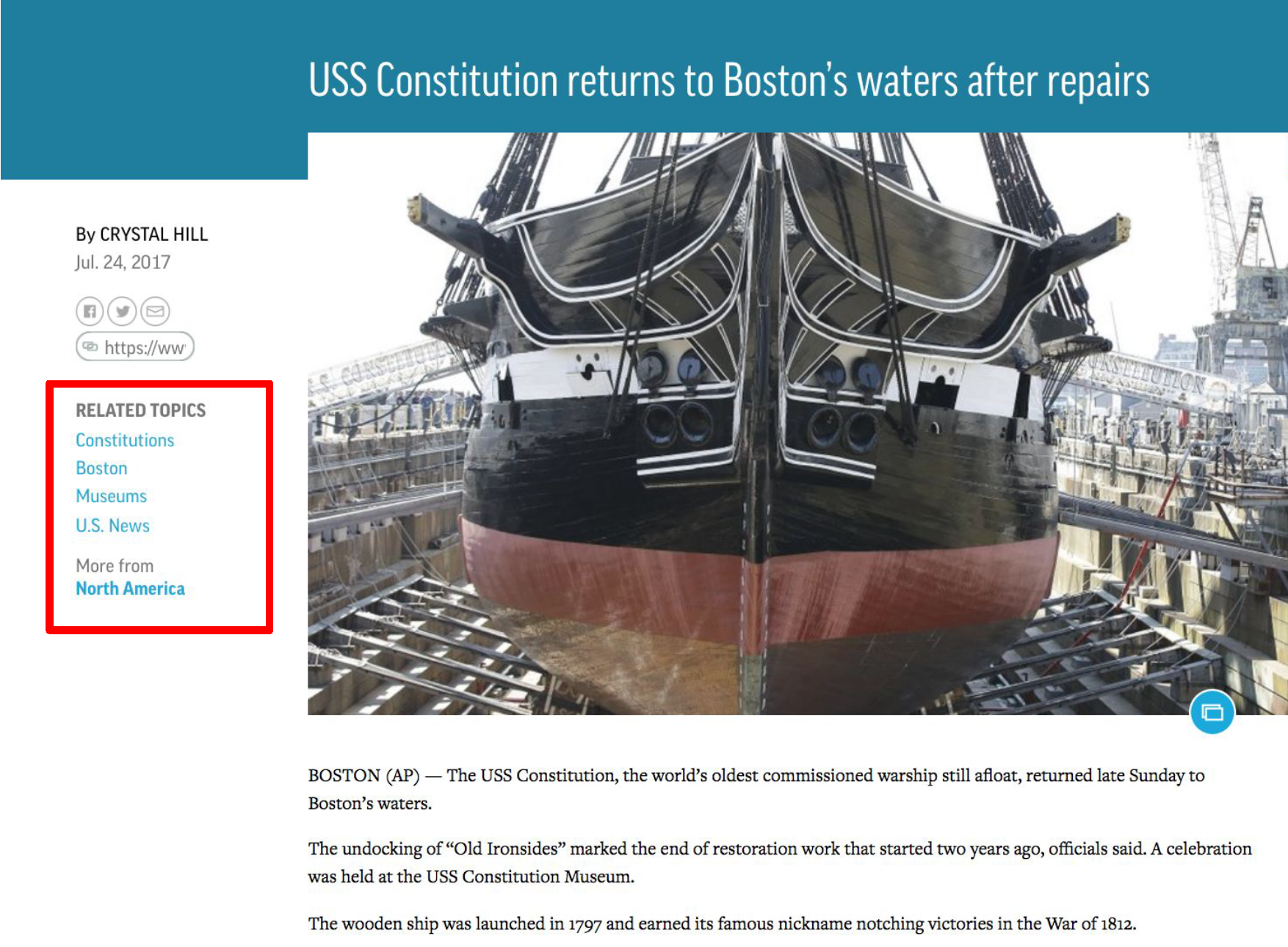
Fig 2. AP Article about the USS Constitution
Addional Motivations
In order to create a better tagging system, we need to first understand what "better" means.
This is why an important aspect of our project is the idea of "ground truth." Aside from
anecdotes and discovered examples like the USS Constitution article above,
we do not have any measure of the accuracy of the AP's current taxonomy and metadata tagging system.
The AP's current methods involve spot-checking current rules and monitoring customer complaints to
measure how well their taxonomy identifies topics and entities within content. They do not have
a formal set of "ground truth" or "gold standard" good and bad tagging examples, which would be
useful for more advanced tagging systems involving supervised learning.
Thus, an important goal for our project is the ability for the AP and their clients to record feedback of both their current tagging system, as well as our project's topic and named entity identification system. This allows individuals to identify good tags and bad tags for any given article and save those in a log. This will ultimately assist in building a ground truth dataset, and hopefully lead to employing semi-supervised methods to dynamically score and rank tags globally across a corpus of content.
These limitations and motivations lead us to the following problem statement:
How can we increase the AP's metadata accuracy and filter relevant tags in order to improve article discoverability, reduce customer complaints, and build ground truth?
Description of Data
Raw Data
In its raw form, the data we used for this project is a corpus of 50,000 .xml files. Each
file is an AP news article that has been passed through the AP Tagging Service and
enriched with metadata from the News Taxonomy. Our corpus contains articles published between
September 2017 and February 2018. Figure 3 contains an excerpt from one such .xml
file, showing
the "SubjectClassification" tags for that particular article.
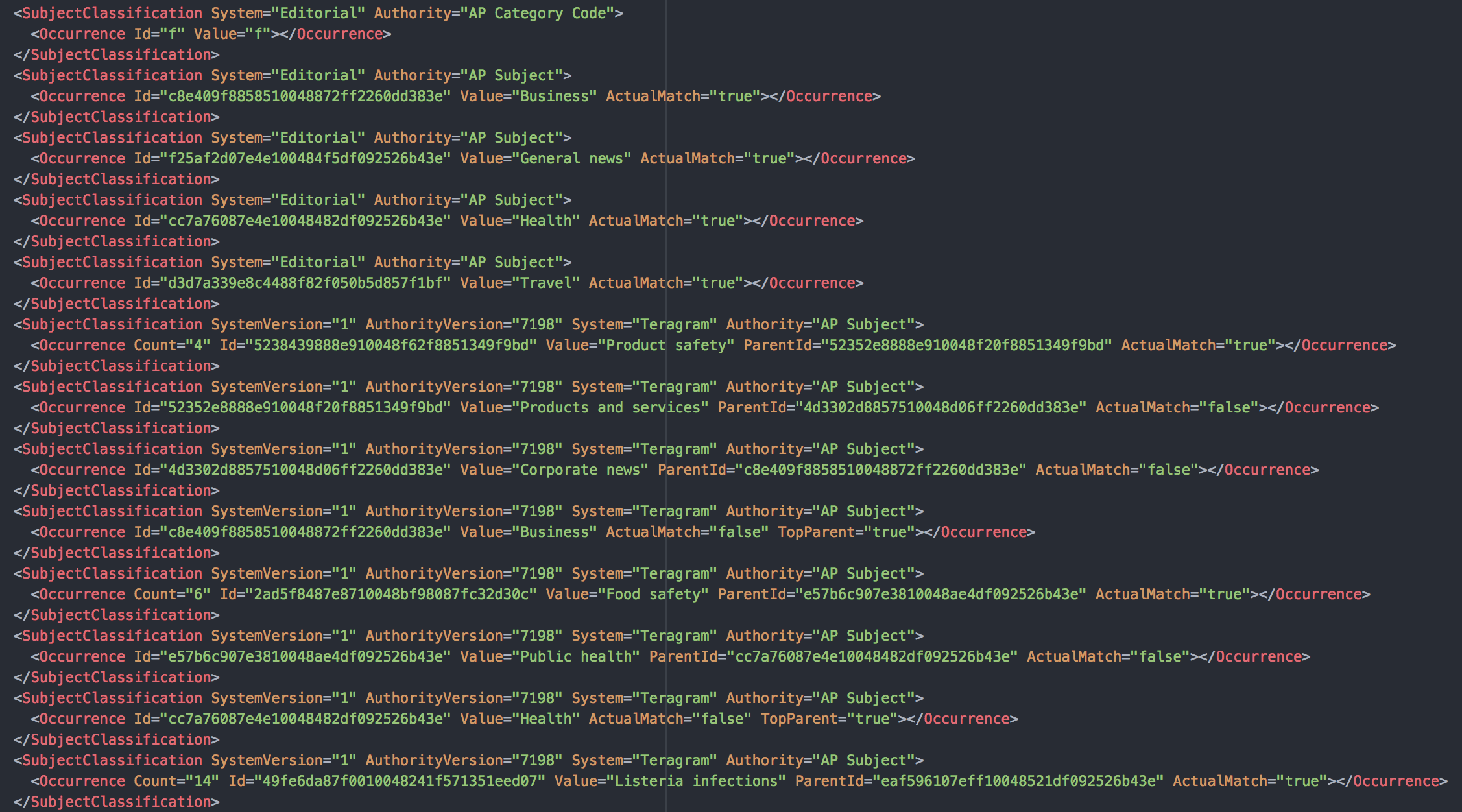
Fig 3. A look at our .xml data and its metadata tags
Processed Data
To explore the raw data, we parsed each file based on its xml structure. We wrote
Python scripts to parse each article into a row of a Pandas DataFrame. This format allowed us
to conduct an exploratory data analysis of our corpus, seen in Figure 4.
We also initially saved the body of each article as an individual .txt file in order to apply
the modeling methods outlined below. For our analysis, we focus specifically
on AP-generated tags categorized as "SubjectClassification" and "EntityClassification." We refer to
these as subject and entity tags, respectively.
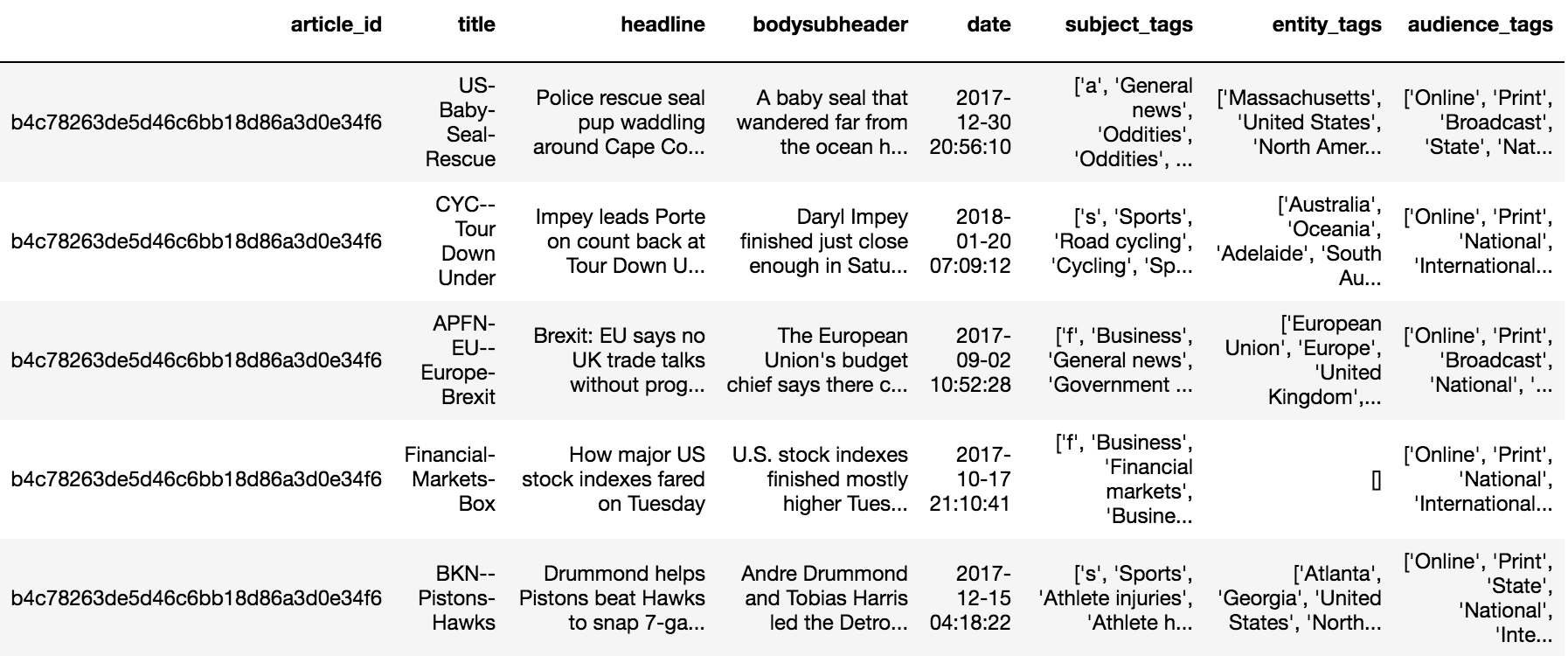
Fig 4. Raw data parsed into a Pandas DataFrame
For the final tagging, scoring, and sorting tool, we use the original .xml file in order to decrease processing time. More details on these methods can be found below.
Visualized Data
When we plot the frequency of subject tags in the corpus, as displayed in Figure 5,
we see the majority of articles are tagged with "Sports," "General News," or "Government and Politics."
This is not surprising, but gives us important information about the distribution of tags within our
corpus.
There are also many single letter tags like "s," "a," and "n." These tags are a part of an international standard developed by the International Press Telecommunications Council and Newspapers Association of America, formerly known as the American Newspaper Publishers Association (ANPA). They refer to categories such as "s" - Sports, including packages, "a" - Domestic, non-Washington, general news item, "n" - State and regional. These tags are commonly included to increase search relevance of AP articles.
It is also important to note that for any given article, there is often significant double tagging for certain categories such as "Sports" or "General News".
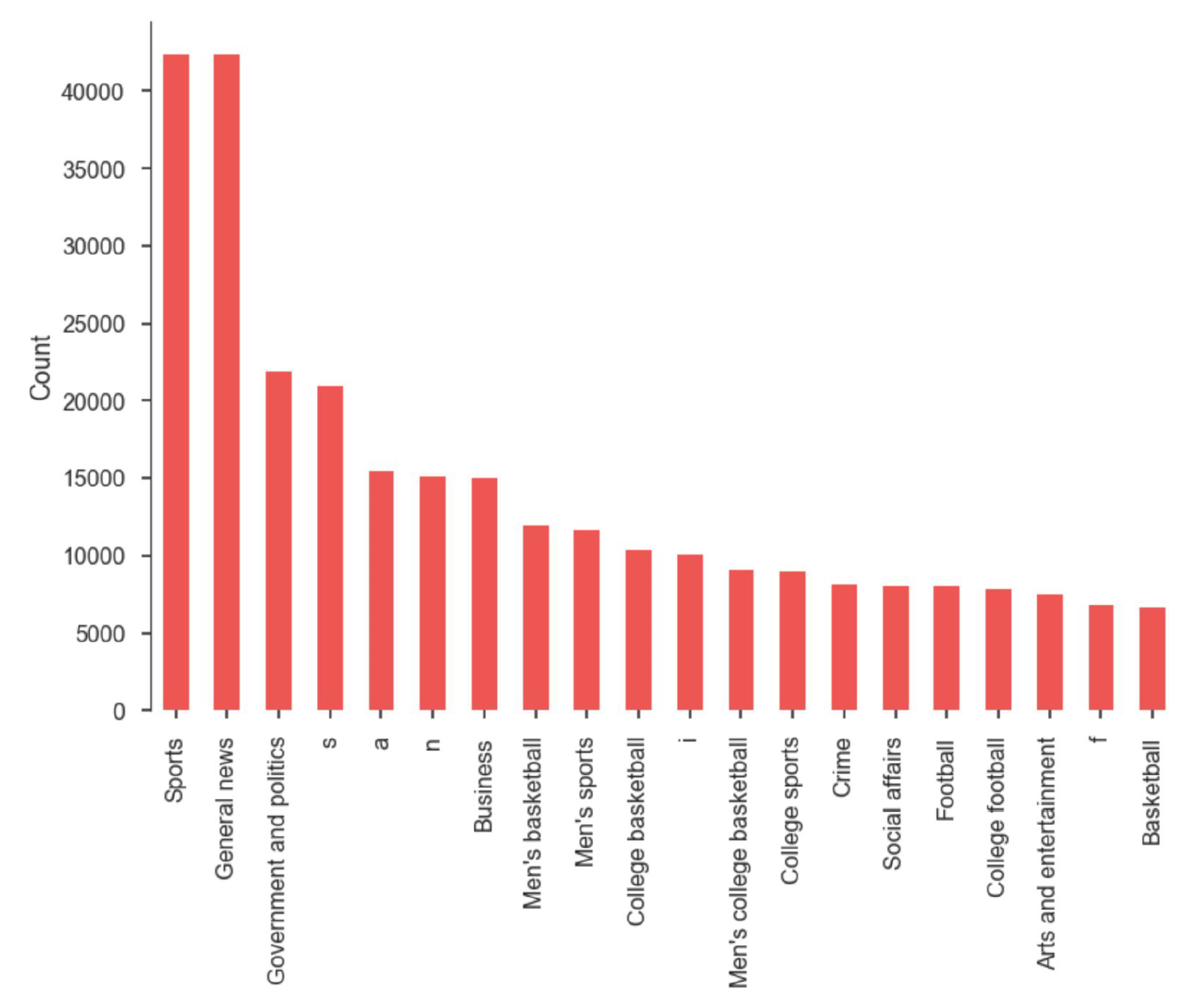
Fig 5. Corpus Subject Tags
The "EntityClassification" tags, seen in Figure 6, contain more descriptive information. They identify proper nouns - people, places, things - a particular article is about.
As our corpus contains strictly English-language content, it follows that the majority of articles have entity tags such as "North America" and "United States." Since our corpus contains stories from a very politicized time period, "Donald Trump" shows up at the sixth most frequent entity tag followed by "National Football League."
Here we display only the most common entity tags. As noted above, there are thousands more within the AP's News Taxonomy.
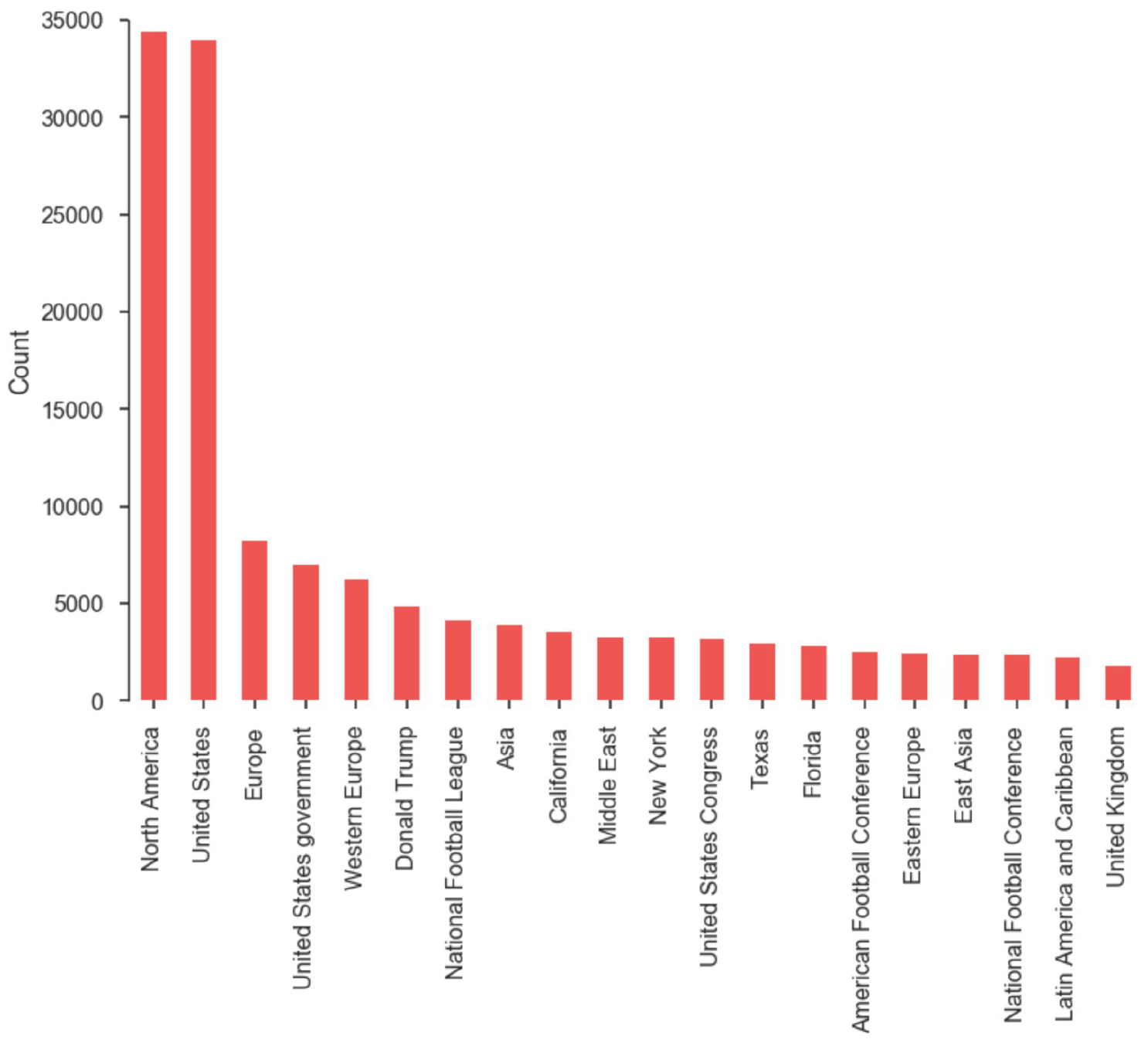
Fig 6. Corpus Entity Tags
Modeling
Identifying & scoring tags
Throughout this project we explored multiple methods for identifying and scoring tags within
each article. An important scoring tool design consideration was identifying tags that are both
locally important (within each article headline and body), as well as globally important (within
our corpus of articles). To that end, we used named entity extraction to identify key terms in each
document, and then compute a term frequency-inverse document weight for each of these terms. We combine this
score with an additional score based on article heuristics to return a list of ranked tags.
Named Entity Extraction
People, places, organizations, and companies are all examples of named entities. We use this concept
to help determine what a given article is about. Named-entity extraction (NEE) is the process of identifying
and isolating these types of proper nouns from a piece of text. We use the Python library
Spacy to extract entities from each article in our corpus.
We intentionally chose to focus on identifying tags based on named entities (similar to the AP's Person,
Company,
Organization, and Geography tags) instead of placing articles into broader categories (like the AP subject
tags),
with the understanding that the former may also be helpful in determining the latter.
Simply extracting a named entity from an article extablishes its local importance, but this is not enough. For example, many articles may mention a person's name, particularly a common one such as Hillary Clinton, without necessarily being about that term. Thus, it is important to have some measure of the global importance of a term, relative to other articles.

Fig 7. Named entity extraction example
Term Frequency-Inverse Document Frequency>
Every word that appears in a document is not necessarily important for understanding what that
document is about. For example, words like "the" or "a" help put a cohesive sentence together,
but do not give us information regarding what an article is really about. Term Frequency-Inverse
Document Frequency (TF-IDF) is a way of determining the importance of a term within a document
and across a corpus of documents.
Our corpus, as outlined above, contains 50,000 articles. For any word in one of those articles, "term frequency" is the number of times that word occurs in that individual document. The "inverse document frequency" is the logarithm of the total number of documents in the corpus divided by the number of documents that contain that specific word. In other words, term frequency signifies how significant a particular word is within a document, and the inverse document frequency of that term represents its significance in the entire corpus.
The product of the term frequency and the inverse document frequency can tell us how rare a word is: the higher the score, the more special it is in that document. As mentioned earlier, a key consideration of the scoring tool must be to analyze a tag’s importance locally as well as globally. TF-IDF helps us achieve that.

Fig 8. TF-IDF formula
Article Heuristics
As previously noted, we also apply article heuristics to augment each entity's TF-IDF score. For
example,
if an entity shows up at the beginning or headline of an article, its score will be increased,
and vice
versa for entities that show up towards the end of an article. The rationale for this
augmentation being that articles typically have their principal topics mentioned earlier in an
article's body. These simple scoring heuristics are easily expanded and tuned.
TextRank
TextRank is an algorithm developed by Mihaelcea and
Tarau
that identifies keywords within a single document. It creates a graph with all words from a document
that may be possible keywords as vertices, and adds edges between two vertices (two possible keywords)
if they occur within a certain window of a predefined size (typically between 2 and 10 words).
An edge would be weighted by the number of times the possible keywords occur within the same window.
The computation for the TextRank score for the vertices repeats until values converge.
TextRank looks at the structure of each article in isolation, while TF-IDF looks at the counts of terms within an article as well as the entire corpus of articles. For this reason we hypothesized that they may work well together. We initially implemented a version of TextRank in which the scoring mechanism for the possible keywords was weighted by a TF-IDF score, but we eventually decided not to continue with this approach because the tags generated with named entity extraction and TF-IDF were more relevant.
Tool
Below you can see a screenshot of our project's final tag comparison tool. There are three ways to view the AP's and our tags:
- Entering a headline and body text of an article
- Using the article ID of an article in the local corpus directory
- Choosing a random article from the corpus
We recommend using the random article functionality to fully appreciate how the AP's and our system's tagging works.
You will notice thumbs pointing up and down next to each tag for both the AP's and our system's tags. By selecting those thumbs you save a vote for or against that tag for that article. These votes are saved in JSON and will be incorporated into a future semi-supervised method of dynamically sorting, ranking, and recommending more tags.
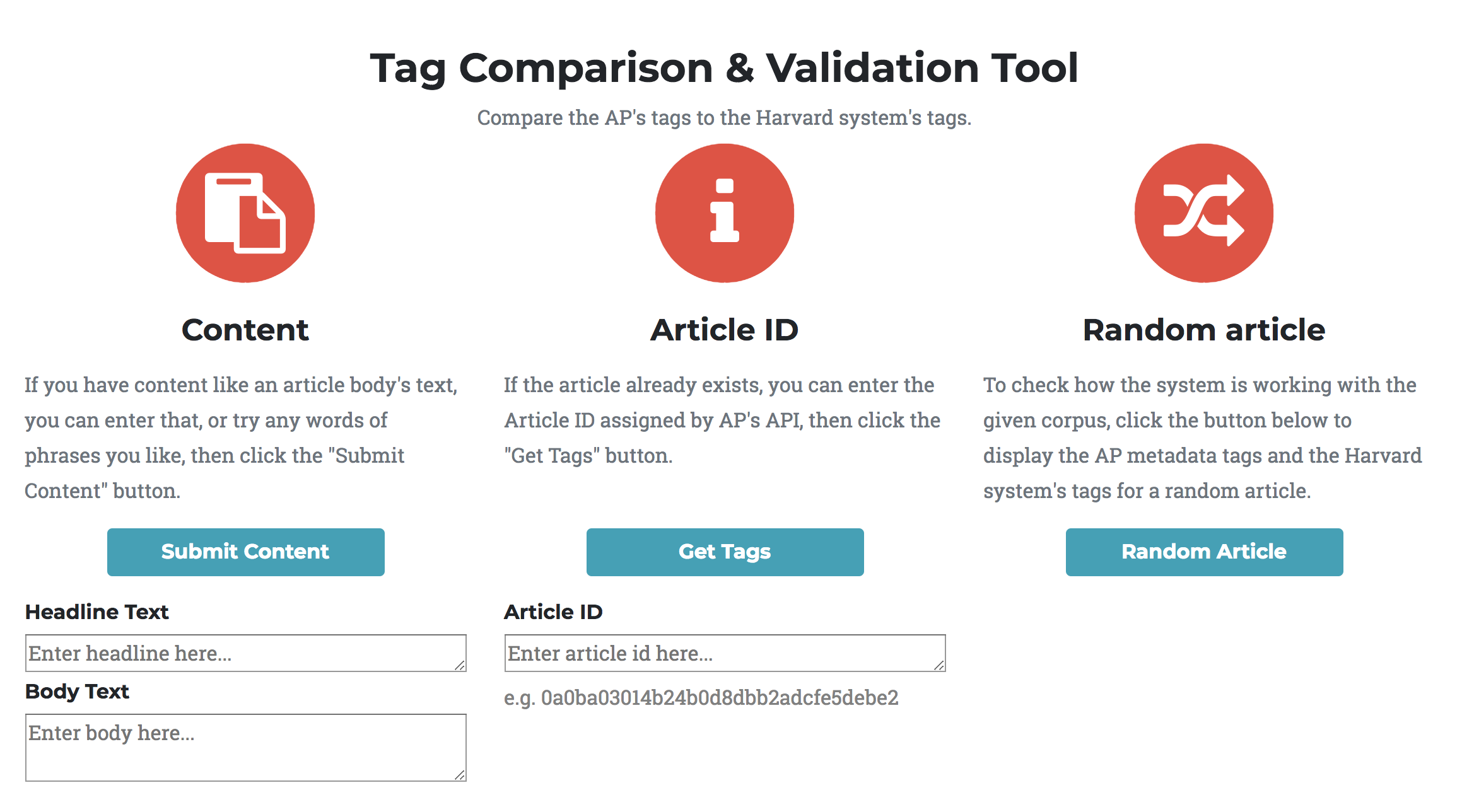
Fig 10. Comparison Tool
Our Process
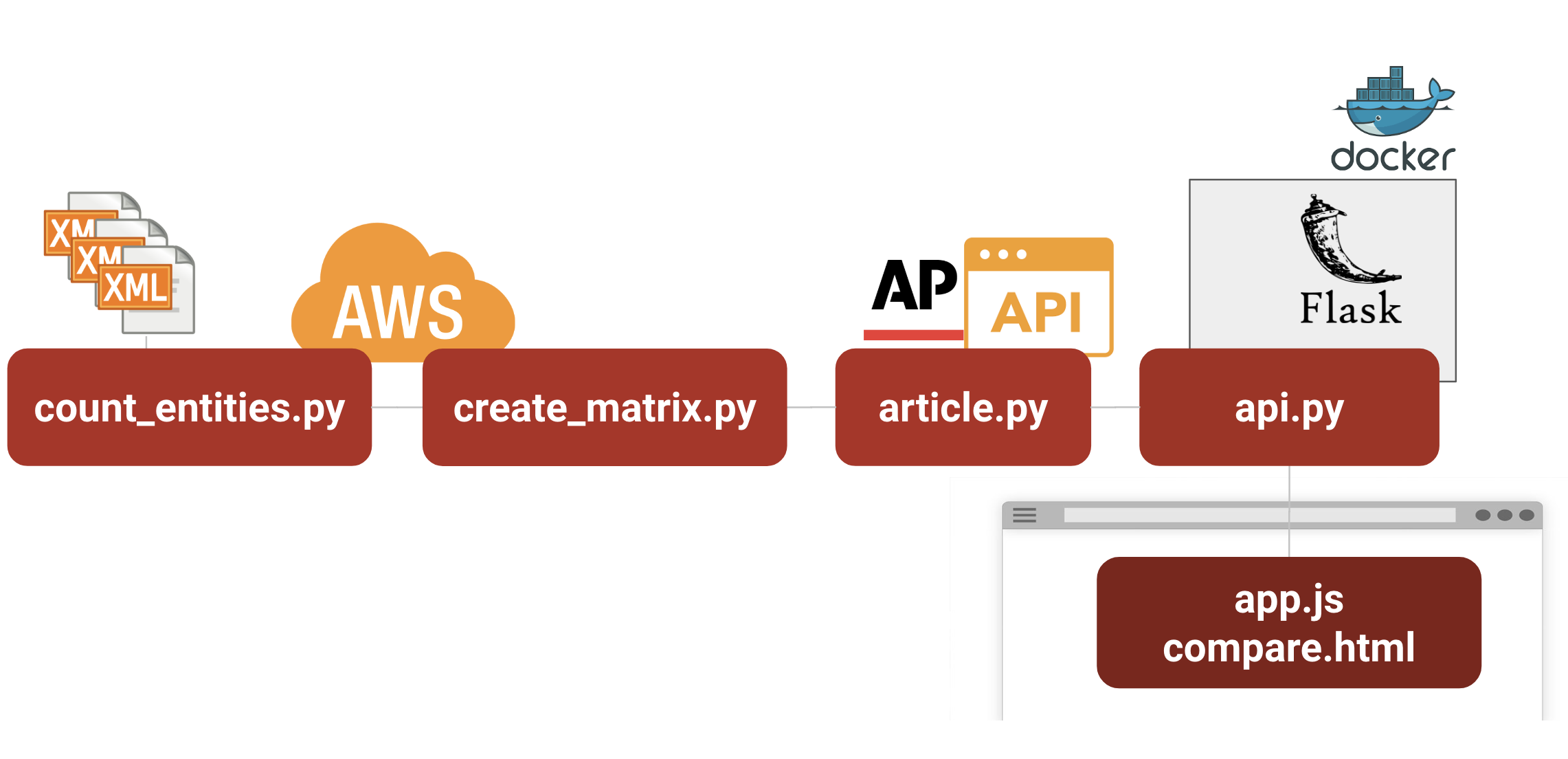
Fig 9. Data Pipeline
Overview
This project is a RESTful API, built with Python and Flask, and containerized with Docker. It
incorporates a modular design, separating the parsing, tag identification, scoring, and sorting
of media files from the web application itself. We use both
Amazon Web Services (AWS) when building
our TF-IDF matrix and the AP's
Metadata Services
API for tagging new content.
Our application uses six primary modules:
This modular design is illustrated above in Figure 9 and explained in detail below. In our project, the media files we are using as a corpus are XML news articles previously enriched by AP's metadata tagging service.
System requirements
To install the tag comparison and validation tool on your local system follow these steps:
- Clone this repository using
$ git clone https://github.com/aefernandes/ac297r.git - Navigate to the cloned repository
- Run
make datato create the data directories (not stored in version control) - Copy any number of article XML files into the new raw data directory — these are assumed to be named
exactly as they were given to us, i.e. `
{articleid}.xml. - Run
docker-compose buildto build the images. - Run
docker-compose up pipelineto do the IDF pre-processing step. - Run
docker-compose up webto do the IDF pre-processing step. - Navigate to http://localhost:5000/ in your browser
- By default, user feedback will be persisted to
feedback.json, but this can easily be pointed to output to a relational database.
Modules in detail
count_entities.pyThis module runs as a standalone script which computes the named entities for each article and seralizes them to disk as an intermediate, compute-intensive step before the "matrix" of document counts and IDF scores. This module was run on an AWS g3.4xlarge instance in order to reduce compute time and ensure adequate memory capacity.
create_matrix.pyThis module runs as a separate utility to generate a scoring matrix based on the counts precomputed by count_entities.py. This helps in fast calculation of TF-IDF score of tags at run-time. This module was run on an AWS g3.4xlarge instance in order to reduce compute time and ensure adequate memory capacity.
article.py: This module is a wrapper around the actual article data covering every aspect of parsing, extracting tags, and other housekeeping. For the purposes of this project, it assumes that it will be processing an XML file on disk somewhere, but can easily be adapted by the AP to process files in cloud filesystems like S3, HDFS, or even stored over the network.
api.py: This is the top-level module in our application. It binds the frontend with the backend. The route() decorators in this class tell Flask which URL should trigger which functions.
app.js: This module has a number of JavaScript functions that connect the web application frontend with the backend, and control how the html page is rendered.
compare.html: This page defines the layout of our web application’s user-interface.
Results & Analysis
The following articles, with the AP's tags on the left and ours on the right, show some interesting results when comparing our system's tags with those identified by AP's taxonomy and metadata tagging system. The entities our system tags are generally more specific than the entities from AP's metadata syste. We have applied votes subjectively, and think these examples do an excellent job of showing the potential of our tool as both an internal rule validation mechanism, as well as client rating system when they add new content through the metadata tagging API.
Many more good examples can be found by using the "Random Article" button in the tool.
Results Example 1: Maroon 5 Manager
Below is an article about the death of Maroon 5 manager, Jordan
Feldstein. The AP's system picks up actor Jonah Hill, and musician
Rick Springfield, but misses the article's main topics - Jordan Feldstein and Maroon 5. Our
system
extracts those tags, as well as Career Artist Management, and Feldstein's other clients like
Miguel and Elle King. These tag differences and additions
are precisely the kind of feedback that would be helpful for management of rules, or
adding our system's tags to their metadata to increase search relevance.

Fig 11. Maroon 5 Manager Example
Results Example 2: London Bombing "Hero"
Below we see another good example of our system finding specific tags that the
AP's did not identify. The article is about the Ariana Grande concert bombings in London,
and specifically a 'hero' named Chris Parker.
The AP's system tags Ariana Grande and the bomber Salman Abedi, but misses ones our
system tags like Manchester Arena, Chris Parker (the main focus of the
article), Manchester Crown Court, and David Hernandez, a judge presiding over Parker's case.

Fig 12. London Bombing Example
Results Example 3: Armistice Day
Next we have an article about Armistice Day, and the French events surrounding it. The
AP's system tags locations and current and former presidents, but misses key topics like
Armistice Day, Champs-Elysees, World War I, George Clemenceau, and the Arc de Triomphe. This is
another excellent example of an article that could greatly increase its search relevance by
including our system's tags within metadata, as well as building ground truth for good tags to
have rules for.

Fig 13. Armistice Day Example
Results Example 4: Egyptian Exchange
Below we have another example of our system finding more specific and relevant tags than
the AP's system. The article is specifically about the Egyptian Exchange. It also has references
to Mohammed Farid, a prominent Egyptian political figure. These tags would be perfect to add
to this article's metadata, as well as build ground truth.

Fig 14. Egyptian Exchange Example
Results Example 5: Police Shooting
Our last example is about a police shooting in a small Ohio town. The AP's system
misses a number of relevant topics aside from the general geographic location of the article -
specifically the police officer, Bryan Eubanks, and the small town the officer worked in,
Newcomerstown. These two tags would greatly focus the search relevance of this article and
direct it to people who would most likely be searching for coverage specifically about Bryan
Eubanks and Newcomerstown.

Fig 15. Police Shooting Example
Recommendations & Future Work
The primary goal of this project was to help the Associated Press establish ground truth as well as increase search relevance of articles. This system will be a great help to the AP in validating the efficiency of their tagging rules, as well as improve their metadata service product by incorporating our tags, as often our system tags relevant entities the AP's tagging service did not. We hope the Associated Press will utilize the feedback mechanism (thumbs up/down) to:
- Compare their tags with tags generated by our system
- Check the efficacy of their tags and update their rules as required
- Collect feedback from clients in a structured manner outside sporatic emails or phonecalls
We recommend incorporating a semi-supervised system that utilizes the feedback collected by our thumbs-up/thumbs-down feedback interface to automatically recompute and update rankings of both our system's tags, as well as those from the AP's system. That system could also make recommendations for tags that were not included by our or AP's system.
We highly recommend that AP incorporate our system's tags into their metadata tagging system. By adding our named entities to their metadata, they will increase search relevance by including entities that may not be found in their current taxonomy.
References
- Harvard University's IACS Capstone course.
- This project's GitHub repository.
- More about the Associated Press.
- More about the AP's Metadata Services.
- Website frameworks provided by BlackrockDigital.
Contact
This project was produced by the following students:
Our team's Teaching Fellow was Isaac Slavitt, co-founder and data scientist at DrivenData.